Callbacks and Hot-Reloading: Must JMP through extra hoops
In this post I describe how, by assembling a little theme park of assembly instructions, some sinister, some not, but all well intentioned, we can coerce the two to find each other.
Requesting a callback is a promise that someone, in the future, will be there to pick up the call. This promise is easily broken in a hot-reloading scenario: every time a module is recompiled and reloaded, the updated callback handlers get mapped to new addresses, and any calls to old, stale, callback addresses crash the program.
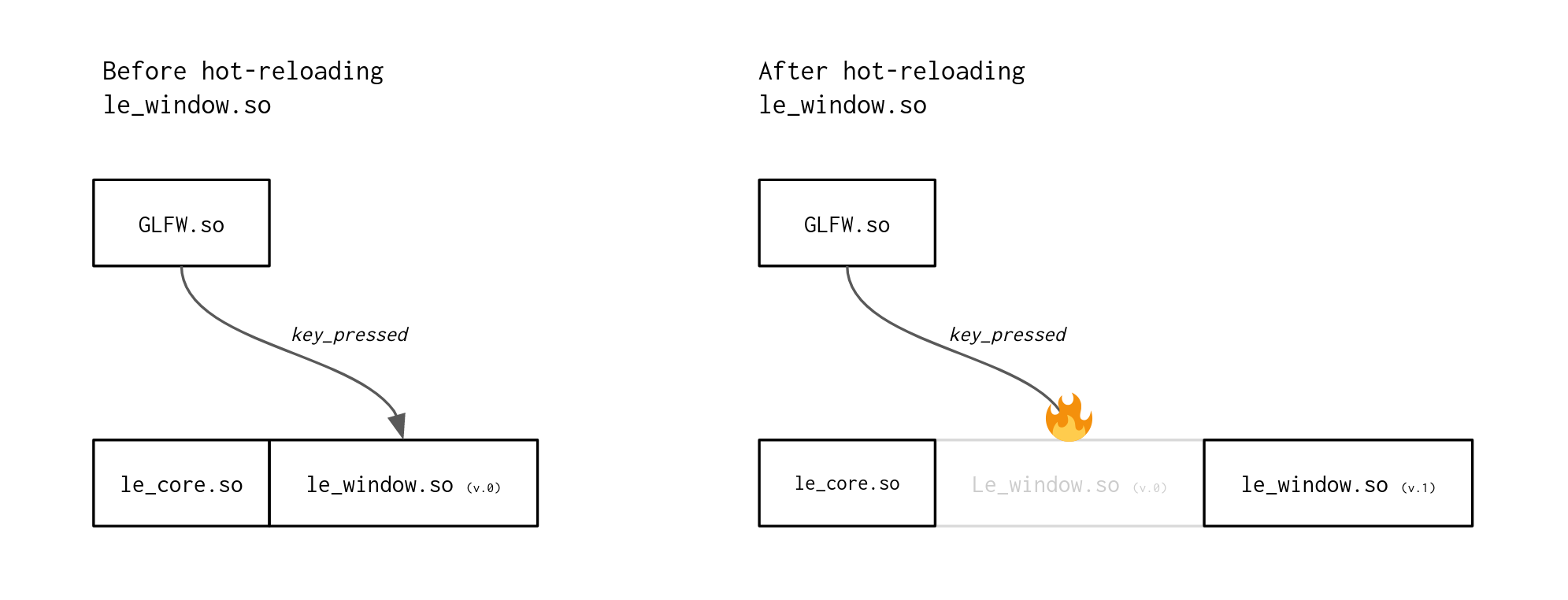
Imagine a situation where you have an external library, say GLFW, that triggers a callback whenever the user presses a key. The callback is set up when GLFW is loaded and the window is created. If the module that implements the callback (le_window in the illustration above) gets hot-reloaded, calls from GLFW will still go to the old address, and that, dear friend, is shaking the tree of pain.
We could tell external libraries to update their callbacks as soon as we detect hot-reloading has happened. But this is not always possible.
Wouldn’t it be nice to have a solution where we can hide all these internal, embarrassing hot-reloading details from external libraries so we don’t have to come back every time that hot-reloading has happened?
A magical proxy
We could solve this by using a proxy or trampoline function. Such a function would need to figure out the current address of the callback handler and forward any calls (including parameters) to this final address. And while this final address can change, the proxy function itself must remain in the same place for the full duration of the program.
This rules out modern c++ trickery: perfect forwarding would still give us templated function implementations inside the compilation unit which sets the callback handler - the same compilation unit which almost certainly gets reloaded whenever the handler gets recompiled.
Okay, so we need to find a module or part of the program which never gets hot-reloaded. By virtue of elimination this leaves only one module: the module which actually implements the hot-reloading.
In Project Island, a hot-reloading Vulkan engine I’ve been working on for a little while, the le_core module fits the bill: Because this core module deals with loading and reloading all other modules and contains the central API registry, it is the only module which cannot be itself be reloaded.

le_core will always stay at the same memory address, regardless of all the hot-reloading going on around it. It is, in fact, responsible for all the hot-reloading. Why not make it responsible for callback forwarding, too, then? (Diagram not to scale)
So that’s where our forwarder will need to live. But how do we get it to actually do what it needs to do?
We ruled out advanced c++ template magic a bit earlier. What’s left? Perhaps we can use assembly?
When out of options, try assembly
In assembly, a JMP instruction is used to jump to an address in code. In contrast to a CALL instruction, it leaves the stack exactly as it is, it just does what it says on the tin: it makes the instruction pointer jump to the target address.
If we can sell our client library the address of such a JMP instruction as the callback address, or maybe an address a little bit earlier, so that we can add a few assembly instructions to resolve the final address to jump to, we would be golden.
Let’s write a POC
Let’s say the goal is to jump to the address that’s held in the global variable target_addr inside le_core.cpp. We write an assembly method trampoline_func, which we can use as a proxy for any callback function. Any call to trampoline_func() shall get forwarded to target_addr().
|
|
Here’s what the compiler/linker has to say to that:
|
|
Daw!! This does not work, because the inline assembler won’t resolve the address of target_addr for us. le_core.cpp is actually compiled using -fPIC, so recompiling won’t help. I’ve tried.
But because target_addr and trampoline_func() are part of the same compilation unit, we should be able to use rip-relative addressing to resolve target_addr.
And indeed, if I calculate the offset manually, and write some assembly that calculates the absolute target_addr by adding the offset to the %rip register, it works. But that’s not practicable, because adding just one instruction will mess up that manually calculated offset, and I would have to recalculate and update the offset manyally, everytime I wanted to add anything to le_core.cpp.
Maybe we can use extended assembly?
|
|
Yes, with extended assembly, magically, we can use globals, and they will resolve to correct rip-relative addresses - the extended asm input variable target_addr, referred to in extended assembly code as “%0”, was translated into the first line of the following assembly listing:
|
|
Because the trampoline is called from inside a function call, it will have added a push rbp instruction. This messes up the stack for the callback function, but is easy to undo: we add a pop rbp instruction just before jumping to our real callback function.
|
|
A Trampoline and a Sled
Next problem: How can we do this for multiple callback functions? Can we figure out a way to use the same forwarder function for each callback?
For the forwarder to be truly useful we need a way to store the actual final callback addresses in an array inside le_core.cpp, and have the forwarder function pick the correct target address. But based on what? We cannot somehow add an extra parameter to the proxy function, because we cannot change the number of parameters of the callback function.
We somehow have to encode an index with the function call, but we can’t save any data with the function call - all we have is the address of the forwarder, which we give to the client.
Wait a moment - can we use this address to encode an index?
Yes we can: we can insert a sled (or should we call it a “ramp”) at the beginning of trampoline_func, so that there are multiple entry points to the function, each entry point setting the %rbp register to a specific value. We can use that value to index into an array of addresses - we can look up the callback target function from our “phonebook” array stored in target_func_addr[], based on the index given in %rbx.
That way, to external libraries, we can hand out unique addresses for forwarder functions , with each address now encoding the index of the target function to call.
|
|
And this is the assembly code generated for void trampoline_func():
|
|
Wrapping up
What’s left to do is some cleaning up, and making it all a bit more ergonomic.
For one, it’s important that we don’t clobber the %rbx register, as it might actually be in use. So that we’re able to restore the original value of %rbx we add an instruction at the beginning of each sled entry which pushes the initial %rbx value to the stack. We then pop that value back into %rbx just before we execute the final jmp instruction.
This means our sled entries will have to look like this:
|
|
And the final jump instruction will need an additional stack pop:
|
|
Another thing to consider is that if we add quite a few sled entries, we will have to modify the formula to calculate the target index. This is because the compiler will issue slightly different machine code based on how far a jump goes.
Sled entries placed in machine code within 128 bytes code of the label sled_end will use a 2-byte machine code instruction for the jmp sled_end assembly instruction, which will makes these sled entries 10 bytes apart in total. Sled entries which are further away from sled_end will need a wider address, for which the assembler will issue a different machine code instruction consuming 13 bytes of machine code.
Putting it all together
Here’s how we use this devil’s concoction to setup a callback which can survive hot-reloading of the module in which it was declared:
|
|
Here are the relevant portions of le_core.cpp which deal with callback forwarding:
|
|
The file sled.asm contains just the code for the sled, which might be a bit repetitive to write by hand:
|
|
This is why I added a python script to automatically generate a sled of the correct length required by parsing le_core.cpp for the value of CORE_MAX_CALLBACK_FORWARDERS:
|
|
Some Caveats
Because this uses assembly, the method presented above is not as portable as it should be - so far this has only been developed for and tested on 64bit Linux.
The assembly instructions used, however, are very simple, and it should be straightforward to port this to systems which don’t necessarily use the System V calling convention, such as Windows.
Tagged:
RSS:
Find out first about new posts by subscribing to the RSS Feed
Further Posts:
- Colour Emulsion Simulations
- Watercolours Experiments
- Vulkan Video Decode: First Frames
- C++20 Coroutines Driving a Job System
- Vulkan Render-Queues and how they Sync
- Rendergraphs and how to implement one
- Implementing Bitonic Merge Sort in Vulkan Compute
- Callbacks and Hot-Reloading Reloaded: Bring your own PLT
- Love Making Waves
- 2D SDF blobs v.1
- Earth Normal Maps from NASA Elevation Data
- Using ofxPlaylist
- Flat Shading using legacy GLSL on OSX