OpenFrameworks Vulkan Renderer: The Journey So Far
It’s been a while. Since I last wrote, the openFrameworks Vulkan renderer has evolved quite a bit.

This latest version feels more modern to use, and the underlying engine should fit Vulkan better.

I wanted the renderer to work well with design principles I found good & useful in openFrameworks, but it’s also ambitious to follow a modern, stateless approach to rendering, similar to projects such as regl.
To me, and probably many others, openFrameworks is very useful as a prototyping environment to bring ideas to life quickly, and then to go deep if needed, to re-work and optimise code for good performance. It’s the “make it work”, “make it pretty”, “make it fast” design/development principle.
Vulkan does not make this easy: it is very explicit, and so impatient to optimise, that it wants to know everything upfront. It is very much a “no-surprises”, “no-sugar” API.
While the oF Vulkan renderer embraces the “no-surprises” policy, it very much tries to sweeten the experience of writing vulkan powered graphics.
Live shader programming, for example, should be quite enjoyable with this renderer.
If you want to check it out straight away, the current dev repository is here, and I’ve added Windows and Linux setup breadcrumbs in the Vulkan renderer specific readme that can help you setting up.
I’ve added a couple of vulkan-based examples into devApps, you will recognise them by “vk” in their name.
I’ve also added a vulkan app template to the project generator, which means you can create an oF Vulkan app scaffold by typing:
projectGenerator/commandline/bin/commandline -t"vk" myNewVkApp
Still here? Brilliant! I might take the opportunity to go into some more detail then, about what the vk renderer currently can do, how some of the parts fit together, and what’s planned next.
Why Vulkan?
Some time before the second rewrite of the renderer, I began to wonder if Vulkan was worth all the extra effort, compared to just stick with OpenGL. And while it’s difficult to predict what you are going to use it for, I found some Vulkan features specially promising for openFrameworks applications:
- Unified shading language for draw and compute (great for particle systems, computed geometry, hybrid ray-tracing and/or ray-marching scenarios, engines)
- Better and finer sync between draw and compute (great for particle systems, physics, engines)
- Head-less GPU rendering (This is great for offline-scenarios, like rendering out an animation to disk as fast as the GPU/CPU will let you)
- Multi-threading by design (great for performance, and battery on mobile)
- Console-style programming on desktop and mobile hardware (removes many limitations of GLES on mobile)
- Run draw and compute in parallel to draw on desktop hardware (great for particle systems, and compute-based culling, for example)
- Run DMA transfers parallel to draw on desktop hardware (this is important for video streamers)
- Better handling of window system integration, tighter render latencies (useful for VR headsets/applications)
Besides, for production apps, Vulkan gives you lots of new ways to get the best out of hardware, and for tailor-made software, the extra verbosity and complexity may be well worth it.
From these opportunities, I tried to figure out some goals for the renderer design.
Goals for the Renderer
First of all, I think, the Vulkan renderer should not be seen as a replacement for the Programmable GL Renderer, just as Vulkan is not an immediate replacement for OpenGL. The Vulkan renderer should focus on the things that Vulkan can do well, and the OpenGL renderers should stay focused on that OpenGL can do well.
One of openFrameworks’ main goals I feeel has always been to make it quick to get to draw something on screen. That’s something the oF Vulkan renderer aims for, too.
And as with the OpenGL renderer, you should always be able to open an escape hatch, and call raw API commands.
What the Renderer Takes Care Of
Here then is a selection of what the openFrameworks Vulkan renderer currently provides. First in a bullet-point summary, then fleshed out to a bit more.
Summary
The renderer gives you a “batteries included” environment with:
- Vulkan.hpp (official Vulkan c++) bindings
- a properly initialised Vulkan device
- loaded with debug layers for Debug App targets
- a swap chain, backed by default render pass
- a default renderpass
- depth-testing and alpha blending on by default
- a fully resizable window
- may go fullscreen
- frame-based memory synchronisation
- a simplified shader input interface (Descriptor handling)
- a modern shader code interface:
- load & compile shaders straight from GLSL
- friendly shader compile error messages
- load shaders optionally from SPIR-V
- re-compilable shaders
- hot-swappable shaders
- dynamic pipeline generation
- simplified memory (sub)allocation with poolAllocators for buffer-, and image memory
- simplified CPU-GPU memory transfers
Vulkan.hpp
The renderer uses vulkan-hpp to talk Vulkan. This C++ API header file was initiated and open-sourced by NVIDIA, and is now officialy hosted by Khronos. It comes with the official Vulkan SDK, and wraps the raw c-header in modern, use-friendly C++.
Default Swapchain
From the outset, you will have a “canvas” to draw with: The Vulkan renderer gives you a default swapchain. A swapchain is a list of images where Vulkan can render into, and which your operating system can grab to display on screen. It’s similar to the system of front- and back-buffers in OpenGL, but gives you more control.
There is, for example, an Image Swapchain. This swapchain allows you to render without a window, straight to an image sequence on disk. The default swapchain, of course, goes to screen.
The renderer will create a swapchain with a flexible number of frames (backed by the right kind of memory), so you can tell the renderer in main.cpp how many frames you want the GPU to have in- flight at any time.
Default Renderpass
The renderer also creates a default renderpass for you, and this default renderpass has a depth buffer, so that you can easily enable depth-testing, if you want.
Memory Allocators
In Vulkan, you have to allocate GPU memory for nearly everything. “Want to set your modelViewMatrix? - You’ll first have to have memory for that. Want to set the modelViewMatrix for another mesh? - You have to have separate memory for that…”
But the spec only guarantees 4096 memory allocations over the full lifetime of your app.
To help with this, the renderer gives you two types of Allocator, one for buffer, and one for image memory. These allocators allow you to grab large chunks of GPU memory, and hand out as many small virtual sub-allocations as you may want.
Frame-based Memory Synchronisation
Once you have allocated memory, and use it to queue up a frame, you need to make sure that this memory is not touched again until the GPU has finished rendering that frame. Many frames can be in flight (meaning, all their memory is owned by the GPU) at the same time. Some engines track the CPU and GPU life-time of every transient memory object, and this can quickly get very complicated, and slow.
Instead of herding and tracking all these tiny objects across frame boundaries, the renderer fences them in, and frees them all at once when the GPU has finished rendering. Then it returns the frame to the CPU.

Forgive me! Image © Acabashi, Creative Commons CC-BY-SA 4.0, Wikimedia Commons
That’s mainly what of::vk::Context is good for. The context owns a big chunk of pre-allocated memory, and that memory is split into equal partitions for each frame which is in flight. While you build up instructions for a frame, the context keeps writing only to the partition owned by that particular frame.
When you send the frame off to the GPU for rendering, and start recording the next frame, the context starts writing again, but now at the beginning of the next partition, which is owned by the next frame.
Once your first frame has finished rendering, all the memory for that first frame can be re-used, and the context starts writing again at the start of the partition owned by that frame. It doesn’t care about deleting anything, it starts writing again at the beginning of the partition. This follows the pattern of a “pool allocator” or an “arena allocator”, if you want.
This means that instead of having many many CPU-GPU sync objects to track memory, the renderer only needs one such sync element per frame, a Fence. Once the GPU crosses the fence, we (or better the CPU) know that the GPU has finished rendering that frame and all its memory can be recycled.
Pipeline Helpers
To keep pipelines somewhat under control, the renderer has a helper to create pipelines, and pipelines created that way come with sensible defaults (alpha blending on, for example). Of course, the helper allows you to further customise your pipelines.
Many Vulkan tutorials suggest you define everything related to the pipeline upfront. But there are good reasons not to want do this in an art / design code context:
Imagine you do some live-coding and update your shader. The shader is the centre part of any pipeline. If your pipeline was set in stone, you’d have to restart your app everytime your shader code changed. Also, the number of possible combinations of shader, pipeline settings, and render passes is huge, and it’s sheer impossible to predict all possible combinations you might want to use and try out during runtime in your code.

That’s why the openFrameworks vk renderer creates Vulkan pipeline objects for you only when a pipeline is first used. After that, the pipeline is cached, and re-used.
Shader Inputs
A sometimes tricky part of pipeline creation is to figure out the correct inputs for your shader. With inputs I mean what you broadly would call “Uniforms” in OpenGL: uniforms, storage buffers, textures, etc.
In OpenGL, the driver was keeping track of all your shader inputs, and there were methods like setUniform(), which don’t exist in Vulkan. Instead, you are supposed to use Descriptors to tell Vulkan where to read data for your uniforms.
True to their name, Descriptors are not very much fun at all to interact with.
Plus, much of the code you have to write in a Vulkan application dealing with Descriptors is essentially repeating definitions which you already gave in the shader.
The openFrameworks Vulkan renderer takes care of this extra double accounting: It uses SPIRV-cross to analyse and look into your shaders, and deals with Descriptors in a very pedantic way, so you don’t have to.
Spriv-Cross
Spirv-Cross is a library hosted by Khronos, which was initiated by @themaister et al. at ARM, and then open-sourced. And it allows us to know an awful lot about shaders at runtime. The vk renderer uses it mainly to analyse shaders. It will print out a list of inputs, how input memory is laid out, and the renderer also knows how much memory to set aside for each binding. All this (and more) analysis is done in the Shader class, by reflecting SPIR-V shader code.
Vulkan, you see, uses an intermediary shading language, SPIR-V. SPIR-V is not exactly readable for humans, but many shading languages compile to it. GLSL, the OpenGL shading language, can be compiled to SPIR-V with the Khronos reference shader compiler, glslang, which comes bundled with the Vulkan SDK. Pretty soon, I bet, you will be able to compile HLSL into SPIR-V, and use HLSL with the openFrameworks Vulkan renderer.
A Modern Shader Interface
Live-coding with shaders can be very rewarding. Instead of waiting for the compiler to re-create your full application and then start it, you save and reload a shader file while your app is running and, bang!, you see the changes you made.
Unfortunately, pure Vulkan would be a pretty hostile environment for this, mainly because changing the shader changes the pipeline object, and the pipeline object needs to be specified upfront, and once it’s set up, a Vulkan pipeline object is compiled into GPU machine code by the driver - and unchangeable.
Plus, you’d still have to translate your GLSL shader code to SPIR-V, since that’s the only shader language Vulkan accepts.
This where the openFrameworks Vulkan renderer steps in: It can compile shader code directly from GLSL. For this, it uses an open source library called shaderc, which is essentially the Khronos reference shader compiler with some Google extensions (which allow you to #include shader includes for example). So yes, the renderer now also includes a compiler.
It will tell you if there is a syntax error in the shader code, and will print out an error message to the console, together with a shader code snippet from around the line where it expects the error to be. This even works for shader files which you included from inside your shader code using the GLSL #include directive.

Once a shader compiles, it gets reflected by spirv-cross, as I describe above, and examined for any “linker” errors. If some were found you’ll see these printed out in the console as well.
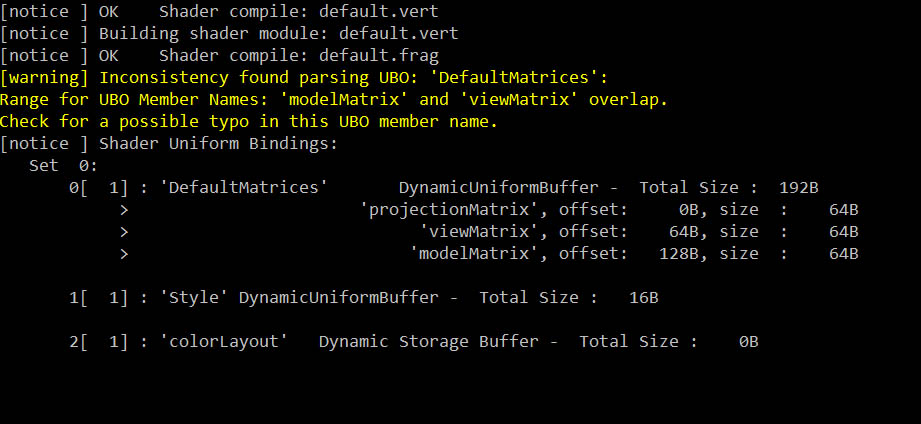
If a shader doesn’t compile, the previous shader version is kept running, so that your app doesn’t need to crash just because of a shader code error.
This means, with the openFrameworks Vulkan renderer, you can now do Vulkan shader live-coding.
It looks as if shaderc will soon support compiling HLSL shader code, too.
What I’ve Learned So Far
I’ll close with a list of points which summarise my experience with Vulkan so far. As with everything in life, the best things are priceless and less nice things overpriced:
Vulkan: The Nice Bits
- better access to hardware
- documentation is amazing, and keeps improving
- nicer unified interface to compute shaders
- control and sync for render/compute/transfer
- allows multi-threaded rendering
- fine control over memory
- meaningful debug messages when using validation layers
- validation layers maintainers are friendly, and quick at fixing issues brought to their attention
- faster than OpenGL when running without validation layers, because then there’s no error checking in the driver
- no surprises: it’s all your fault.
Vulkan: The Less Nice Bits
- complexity (mostly due to synchronisation)
- verbosity
- because of 1, and 2: hard to provide a dynamic environment for prototyping
- “undefined behaviour” - uncaught errors lead to surprises
- surprises: it’s all your fault.
What’s Next
In a future post I’ll try to go into a bit more detail about the way drawing, and the underlaying engine works, and what led to the current look of the draw interface.
I’m also working on getting external addons to work with the Vulkan renderer, such as ofxImGui, which brings dear imgui to oF.

Further References
Over time, I’ve gathered a few resources around Vulkan. I’ve collected them on are.na, here. Of all these Resources, the meta-list awesome-vulkan, curated by Vinjin Zhang, deserves a special mention.
Thanks
I’d like to thank Arturo Castro for mentoring & insights into software architecture. I’d also like to say thanks to James Acres for sharing his enthusiasm for rendering techniques, for ideas and urls around Vulkan and rendering engines, and for brilliant discussions across probably three time zones.
I’d also like to thank the folks at Khronos for organising the Vulkan developer meetups in Cambridge, and for making these open to anyone.
Tagged:
RSS:
Find out first about new posts by subscribing to the RSS Feed
Further Posts:
- Colour Emulsion Simulations
- Watercolours Experiments
- Vulkan Video Decode: First Frames
- Fractures
- Vulkan Render-Queues and how they Sync
- Rendergraphs and how to implement one
- Poiesis - A Real-Time Generative Artwork
- Consider the Lobster
- 2D SDF blobs v.2
- Love Making Waves
- 2D SDF blobs v.1
- Physarum Simulations
- Simulated surface crazing using a fragment shader
- New Order
- World
- Presidential Holiday Trees
- High Flying Ultrabooks
- Ghost
- Supermodel Interactions
- The Making of a Cannon